E-Commerce is a relatively new area of free trade agreements. The WTO first established a comprehensive work programme on e-commerce in 1998. At the WTO Ministerial Conference in Buenos Aires in 2017 a group of WTO Members agreed to start exploratory talks on e-commerce. Negotiations over a potential multilateral rulebook on e-commerce have been ongoing ever since. In 2019, for example, the EU tabled its proposal on a comprehensive set of commitments for WTO Members on areas such as Consumer Protection, Spam emails, Privacy, and Customs Duties.
One of the challenges these negotiations have to overcome consists of finding common ground in the diverse positions states have adopted in their bilateral and regional free trade agreements. We therefore set out to analyze existing treaties that dealt with e-commerce to find whether there were currently any treaty provisions that benefit from widespread adoption. This blogpost details how we assembled our dataset, analyzed individual provisions, produced an interactive database analysis tool, and sets out a few of our findings.
Assembling the Dataset
First, we began by reviewing the secondary literature on e-commerce provisions in trade agreements (see especially Willemyns, and Burri & Polanco) to recognize prominent issues and trends and to more efficiently navigate the treaties. Second, we created a custom corpus of e-commerce provisions. We limited our analysis to treaties with a dedicated chapter or section on e-commerce drawing from the Text of Trade Agreements (ToTA) dataset (up to 2015) supplemented with recent agreements. Each e-commerce chapter or section was broken down into individual articles with article titles. Our final dataset consists of 64 treaties, with 725 articles total, and 94 countries represented. One key limitation of our dataset is that it deals exclusively with English language treaties, omitting agreements signed exclusively in Spanish, for example.
Categorizing by Article Title
Next, we manually categorized each article based on its article title. Categorization is always tricky and somewhat subjective, even more so when looking at negotiated texts from a wide range of regions. We used existing empirical studies as a starting point to create our own categorization system. Every article header was then manually classified independently by two coders. On the few headers where the coders disagreed, the categorization was adjusted to resolve the disagreement.
Regexification
We then set out to automate this classification process so that it could be applied to future treaties. To do so, we developed a set of keywords that were exclusive to each article title category. We then turned those keywords into a “regular expression.” (See Data Science for Lawyers Lesson 3 – Regular Expressions.) REGular EXpressions, or REGEXs, take normal words and turn them into a searchable phrase that R code can understand and use. Regexs essentially allow for highly complex CTRL+F searches. For a simple example, if we wanted to search for “Red Apples”, our equivalent regex would be “Red\\sApples” (\\s is essentially interpreted as a space). We took our newly developed regexs and ran them on our dataset and verified that the machine produced categorized list matched our manually produced list exactly.
The website Regexr allows you to create and test your own regular expressions in real time!
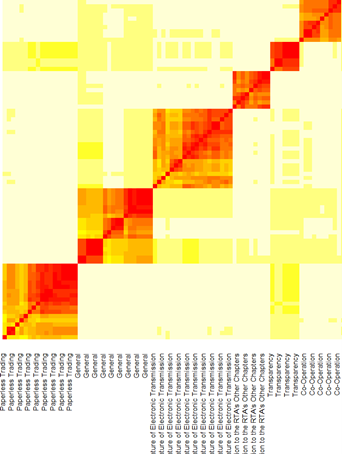
Validating Categories through Textual Similarity Heatmap
To ensure that we classified articles correctly, we used a textual similarity analysis to compare the article texts across our categories. (See Data Science for Lawyers Lesson 6 – Similarity.) Our expectation was that article texts should be similar within categories and dissimilar across categories. We thus produced heatmaps that would group together the article texts that were most similar to each other. This method is thoroughly described by Nicolas Kasting’s “Constitutions as Data (IV)” post.
If the textual similarity ordering closely resembled our assignment of categories, we knew we were on the right track. We iteratively changed our categorization until we were satisfied that we grouped the appropriate articles together for further analysis.
Subcategorization by Article Text
Categorization by article title was only an initial step to help us get the lay of the treaty landscape. Our next move was to mine the article text itself – to see what the treaties say.
We once again referred to the literature to get a feel for what kinds of things the treaty text would talk about in each of our categories. We then began probing the article text ourselves to create a subcategory list for each category. Our end result was a list of parent categories that each had several unique subcategories assigned to them.
Our goal was not to entirely describe the article text, but to capture key signposts for easier treaty navigation. Treaties use a wide variety of language to describe obligations which results in a wide range of “bindingness” on the parties themselves. We simply wanted to be able to quickly point to the appropriate articles and let the reader decide for themselves what the treaty text, read in context, is likely to mean.
Once we were satisfied with our initial subcategory list, we once again created our regexs for each subcategory. This time, however, we did not search for each subcategory in each treaty article. Instead, we ran the subcategory regex only on the text of the articles which we previously marked as the parent category. We had to narrow which articles we were searching to prevent a large number of false-positives resulting in incorrect subcategory assignment. It would be nearly impossible for many of the subcategories to create a regex that would be narrow enough to avoid similar wording in other categories (false-positives) but wide enough to capture everything we wanted in the parent category (avoiding false-negatives). Running our regexs only on article text flagged as the parent category helped us craft simpler regexs while avoiding both false-positives and false-negatives.

The actual coding to get certain regexs only running where other certain regexs were run turned out to be complex. The R code itself is explained in a separate technical blog post.
The product of our subcategorization was a CSV file of all the articles assigned both a category and subcategories. Excel, however, is not the easiest or most intuitive way to investigate a CSV like we produced. While all the data was there, it was not easy to manage or navigate. We had to move beyond Excel and create a proper investigation tool.
Creating a Dashboard using Shiny
Shiny is an R package that allows for the creation of interactive web pages and dashboards from within R without the need for HTML or Java coding. Using Shiny allowed us to create a much more intuitive front end to analyze our data (without having to rewrite our code each time we wanted to investigate something closer), while maintaining the flexibility and power of the R code backend. On the fly plotting, heatmap creation, and subsetting were all soon possible.
Our final Shiny app allowed us to filter by category, subcategories, countries, and treaty regions, while providing the article text for verification of our results by the reader. We were able to produce a heatmap for any subset we selected. We were better able to examine the regionality of our dataset to ensure our analysis was representative. The app told us the percentage of WTO members that our dataset captured. The app also enabled us to better investigate shifts and trends in e-commerce treaties over time with automatic creation of plots comparing both the raw frequency of certain categories or subcategories over time and their relative prevalence in treaties over time.
Iterative Approach
Throughout the process, we iteratively revisited our categories and subcategories. Treaties from different countries often dealt with the same matter under different article titles. What might work for analysing the EU treaties would not accurately capture an East Asian treaty. Often, we found that it was better to have more inclusive (and consequently more abstract) categories than the more narrowly focused categories we began with. Wider categories ensured that our subcategories were both unique to the category while also being properly captured by the regexs. Our final mapping consisted of 20 categories and 70 subcategories.
Findings
We found several areas of that were widely adopted by states and that could be candidates for multilateralization at the WTO level. Provisions dealing with paperless trading and electronic authentication and signatures had widespread support, were highly similar, and were present in a high number of treaties. Countries also consistently agreed to not impose customs duties on electronic transmissions, in line with the WTO work programme on e-commerce.
One of the most interesting patterns we observed was the change in focus of the e-commerce treaties over time. The most convergent areas in the older treaties tended to relate to making the process of doing business easier. Newer e-commerce chapters, however, have begun to create new provisions focusing on the capitalization of data as an asset and data governance (such as privacy, spam regulations, source code requirements, and data localization). Most countries agreed, for example, that some form of personal data protection was required, but there was no agreement on how personal data would be protection. While it is too early to identify any convergence in these new issues, we suspect new treaties will more regularly deal with those new areas.
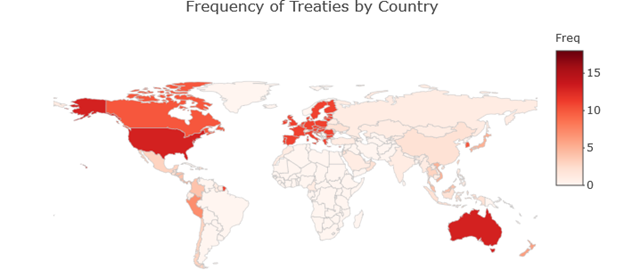
Finally, we found several interesting geographic trends. First, North American countries tended to have treaties with a wider range of partners. Australia, which had the second most (13) treaties in our data set, mostly partnered with East Asian countries. Singapore had signed the most treaties (18) and featured as a global hub for e-commerce.