Introduction
Similarity measures are an extremely powerful tool to investigate legal content. Law, whether in contracts, statutes, treaties or cases, is rarely built from scratch. Instead, legal language draws on precedent, follows established meanings, abides by formalistic drafting conventions, and is often modeled on boilerplate texts. Similarity measures exploit these patterns. They quantify to what degree a contract or treaty follows a model and help identify unique passages; they help identify court decisions that address similar legal issues, track legal innovation or reveal sub-groupings of documents within a large corpus. In short, similarity measures are a useful and very versatile tool for automatically investigating legal texts.
An Example: Mapping Investment Treaties
Similarity analysis brought me to legal data science in the first place. Together with Dmitriy Skougarevskiy, an Economist, I began investigating the universe of bilateral investment treaties through simple similarity measures. We showcase our results on the interactive website www.mappinginvestmenttreaties.com.
What struck me was how a simple measure — how different are the texts of agreements — could reveal so much. We found that the investment treaty universe is marked by power asymmetries with developed states acting as rule-makers and developing states acting as rule-takers, traced changes in underlying investment policy programs of states across the world, and quantified the degree of language innovation in the recently concluded Transpacific Partnership Agreement.
What we do in this lesson
In this lesson, we provide you with all the necessary tools to conduct similarity analyses in the same spirit.
1. Preparing Metadata
2. Creating a Document-Term Matrix
3. Creating a Similarity Matrix
4. Visualizing Similarity Through Heatmaps
Useful Resources
Wolfgang Alschner and Dmitriy Skougarevskiy, “Mapping the Universe of International Investment Agreements”, Journal of International Economic Law, Vol. 19, No. 3, 2016, pp. 561-588. [SSRN Version]
Wolfgang Alschner, “Sense and Similarity: Automating Legal Text Comparison”, in: Whalen (ed.) Computational Legal Studies: The Promise and Challenge of Data-Driven Legal Research. [SSRN Version]
R Script
Preparing Metadata
To make sense of similarity patterns in legal documents, it is essential to start by extracting metadata. Meta data is the data that describes a document which often includes dates, sources and content.
For today's lesson, we will be working with Canadian labor agreements. Please download them and upload them into R.
# Load readtext package.
library(readtext)
# Load treaties into R.
folder <- "~/Google Drive/Teaching/Canada/Legal Data Science/Labor Agreements/EN/*"
# Upload the texts from that target folder.
treaty_texts <- readtext(folder)
To enrich our subsequent analysis we want extract meta data from the treaties. Take a look at the treaty file names. They already contain vital mata data, such as parties and the year of signature. We can thus use regular expressions (Lesson 3) to extract that information from the file names.
# We start by creating two empty objects to which we will add the meta information.
treaty_partner <- character()
treaty_year <- numeric()
Next we loop through all treaty names and extract partner state and year.
# We extract partner and year from each file name and then add it to the empty objects before proceeding to the next file name.
for (treaty_name in treaty_texts$doc_id) {
treaty_name <- gsub(".txt|CDA-","",treaty_name)
partner <- strsplit(treaty_name, "_")[[1]][1]
treaty_partner <- c(treaty_partner,partner)
year <- as.numeric(strsplit(treaty_name, "_")[[1]][2])
treaty_year <- c(treaty_year,year)
}
Then we attach the two vector objects we fill with metadata to original dataset.
treaty_texts <- cbind(treaty_texts,treaty_partner)
treaty_texts <- cbind(treaty_texts,treaty_year)
Now we have a dataframe not only with the full text, but also with helpful metadata. For example, we can now organize the treaties by the year they were signed.
# Order by treaty year.
treaty_texts <- treaty_texts[order(treaty_texts$treaty_year),]
Creating a Document-Term Matrix
We can now turn our treaty texts into data in order to prepare the similarity analysis. Similar to Lesson 5, we want to represent the texts as word frequency counts. This time, however, our focus is not on the terms but on the documents. So we create a Document-Term Matrix -- the simple inverse representation of a Term-Document Matrix.
We again start by creating a corpus object.
# Load package for text processing.
library(tm)
# We start by creating a corpus from the text.
corpus <- VCorpus(VectorSource(treaty_texts$text))
We then pre-process our treaty texts.
# Again, we get rid of variation that we don't consider conceptually meaningful.
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
We now want to use our corpus to create a Document-Term Matrix (DTM). In that matrix, every row is a document (here, a treaty) and every column is a term. The values are the frequencies of each term in a document.
# Create a document term matrix.
dtm <- DocumentTermMatrix(corpus)
While the above DTM can be used for further analysis, we often want to refine that matrix. Imagine, for instance, that you want to investigate the content of 100 documents. You are not interested in outliers but want to get a general sense of what is in these documents. In that case you may want to exclude all terms that only appear in one or two documents. You can do that by changing the lower bound of the control = list() function, which by default is set to 1 (i.e. all terms that appear in at least 1 document).
# For example, we restrict our analysis to all terms appearing in 2 or more documents.
dtm <- DocumentTermMatrix(corpus, control = list(bounds=list(global = c(2, Inf))))
# Finally, we transform the dtm from dataframe to numerical matrix.
dtm <- as.matrix(dtm)
Distance Measures I
When the textual similarity of documents is discussed, it is often done by refering to their "distance". The method intuits that similar documents will be "closer", and have a lesser distance, while for less similar documents will be "farther" and have a greater distance. Think of the word frequency counts of the DTM as the coordinates of each document in a vector space. Where these counts are identical, the two documents will occupy the same coordinates; if some counts differ, and others are the same, the two documents will be further apart, but not too distant; yet if the counts are very different and many terms exist in document A but not B, the coordinates of these two documents will be very far apart.
Statistical distance measures quantify this difference. They calculate how far apart two documents are based on their term frequency counts.
There are many different distance measures. We are now using a unigram representation of the texts. In that context, cosine similarity is often used to calculate the distance between documents. Here, however, we opt for a simpler binary distance measure that allows us to calculate the distance between documents by determining how many words, regardless of their frequency, are present in both documents. This distance measure is known as Jaccard distance. Jaccard distances have the useful advantage of being a measure between 0 (no distance, perfect similarity) and 1 (no similarity).
We thus create a distance matrix using our DTM as input.
# Create binary distance matrix checking whether or not a word appears in a document.
distance_matrix <- as.matrix(dist(dtm, method="binary"))
We can study the distance matrix in its own right. For instance, take a look at min() and max() values for the matrix to determine which treaties are closest and furthest apart. In other words, it helps us determine the similarity of the documents.
Often, however, it is easier to visualize a distance matrix. But before we do so, let's look at a more sophisticated way of calculating distance.
Distance Measures II
In law, context often matters, and as such a word frequency representation may not have enough detail to assess the similarity between documents.
Instead, we can represent text through its constituent characters. The term "legal data", represented through its 5-character components, for example, would be "legal", "egal ", "gal d", "al da", "l dat" and " data". By calculating the Jaccard distance between these 5-character components, we can arrive at a more fine-grained comparison of text that takes word order into account.
Note, however, that this is more computationally intensive. It will thus take considerably longer than calculating Jaccard distances between unigram representations of text.
We use the package "stringdist" to compare the Jaccard similarity distances between treaties represented as 5-character components.
# Load packges
library(stringdist)
# Create a distance matrix
distance_matrix_5gram <- stringdistmatrix(treaty_texts$text,
treaty_texts$text,
method = "jaccard",
q = 5)
Visualizing Similarity Through Heatmaps
Heatmaps are a convenient way to visualize Jaccard distances. They color code high similarity (low distances) red and low similarity (large distances) yellow. We need two graphic packages to visualize the heatmap.
# Load packages.
library(ggplot2)
library(gplots)
Now we can visualize the distance matrix as a heat map. We start with the unigram distance matrix of the labor treaties.
heatmap.2(distance_matrix,
dendrogram='none',
Rowv=FALSE,
Colv=FALSE,
symm = TRUE,
trace='none',
density.info='none',
main = "Similarity labour treaties",
labCol = paste(treaty_texts$treaty_partner,treaty_texts$treaty_year,sep="-" ),
labRow = paste(treaty_texts$treaty_partner,treaty_texts$treaty_year,sep="-" ),
cexRow = 0.6,
cexCol = 0.6)
##
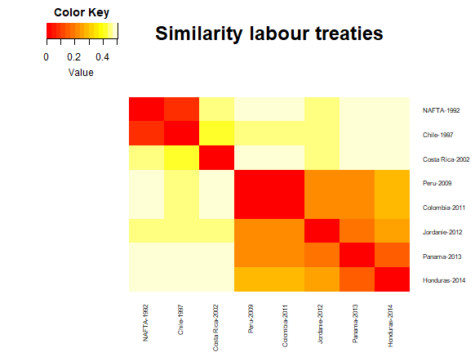
The heatmap is symmetrical, meaning that both axes display the same information and follow the same order. Here the heatmap is ordered chronologically from the earliest labor agreement (NAFTA 1992) to the latest (Honduras 2014). Based on the heatmap, we can identify three generations of Canadian labor agreements. The first is the NAFTA and Chilean treaty, which are both similar. The second one is made up Costa Rica agreement, which differs from all other agreements in our dataset. The third regroups all treaties signed since 2009.
Now we pass on to the more detailed heatmap of the labor treaties represented through their 5-character gram components.
# no dendogram displayed. # column clustering. # row clustering. # heat map title.
heatmap.2(distance_matrix_5gram,
dendrogram='none',
Rowv=FALSE,
Colv=FALSE,
symm = TRUE,
trace='none',
density.info='none',
main = "Similarity labour treaties",
labCol = paste(treaty_texts$treaty_partner,treaty_texts$treaty_year,sep="-" ),
labRow = paste(treaty_texts$treaty_partner,treaty_texts$treaty_year,sep="-" ),
cexRow = 0.6,
cexCol = 0.6)
##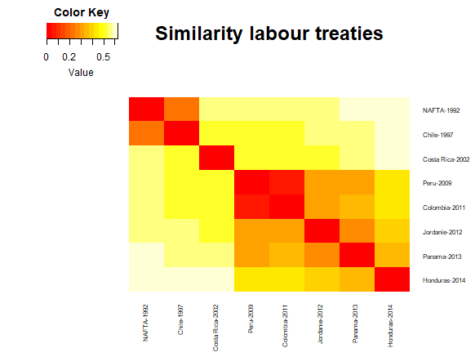
The overarching patterns are similar, but the results allow for a more refined comparison. The three generations still come out clearly, but we see an additional pattern which shows that the Peru and Colombia treaties are extremely similar - more so than any other agreement. In addition, the Honduras treaty, although similar to other agreements signed since 2009, appears more different than the prior heatmap suggested. This could indicate a movement towards a fourth generation of treaties.
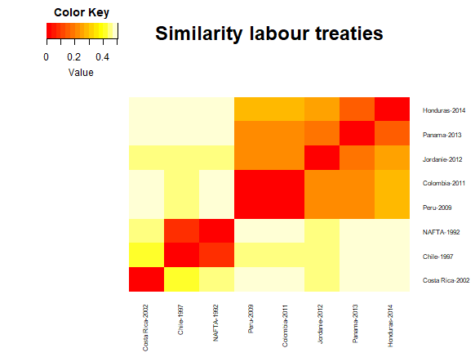
Importantly, our heatmaps have, up to now, been order based on the original dataframe. If we want to order our heatmap by similarity, we need to activate the hierarchical clustering built into the heatmap.2 algorithm.
heatmap.2(distance_matrix,
dendrogram='none',
Rowv=TRUE,
Colv=TRUE,
symm = TRUE,
trace='none',
density.info='none',
main = "Similarity labour treaties",
labCol = paste(treaty_texts$treaty_partner,treaty_texts$treaty_year,sep="-" ),
labRow = paste(treaty_texts$treaty_partner,treaty_texts$treaty_year,sep="-" ),
cexRow = 0.6,
cexCol = 0.6)
##
Dataset
Sample of Canadian labour treaties. [Download]